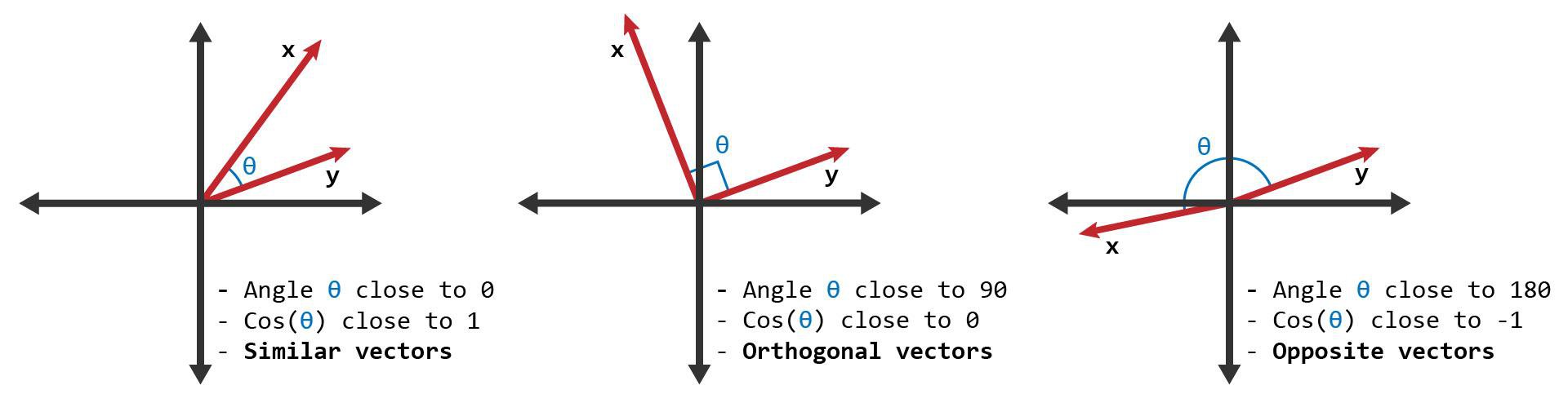
Formula
Cos(x,y)= x.y ∕ ∣∣ x ∣∣ ∗ ∣∣ y ∣∣
Restaurant Recommandation App
Cosine similarity is a metric, helpful in determining, how similar the data objects are irrespective of their size. We can measure the similarity between two sentences in Python using Cosine Similarity. In cosine similarity, data objects in a dataset are treated as a vector.
For example, in information retrieval and text mining, each word is assigned a different coordinate and a document is represented by the vector of the numbers of occurrences of each word in the document. Cosine similarity then gives a useful measure of how similar two documents are likely to be, in terms of their subject matter, and independently of the length of the documents. The technique is also used to measure cohesion within clusters in the field of data mining.
One advantage of cosine similarity is its low complexity, especially for sparse vectors: only the non-zero coordinates need to be considered.